![]()
股票杠杆
杠杆炒股,股票融资!

当前位置:正文
5款大模子,马斯克的grok1竟是一个复读机?

就在最近,国产大模子Kimi再次引爆了公论。
3月18日,月之暗面晓喻其对话式AI助手居品Kimi智能助手现已搭救200万字的无损高低文输入。这个互异化的“长文本处理”的免费大模子,一下子就火出了圈。
这意味着什么?以往需要一个外行进入10000小时能力成为某限制的内行表率,目前你只需10分钟的时辰向Kimi提供酌量贵府,其便可以达到一个全新限制的低级内行水平。
免费+好用,Kimi的处事器短暂就被挤宕机了,官方迫切扩容了五次,才算是规复时时。
(目前我还在内测列队中)
自2024年启动,各家的大模子开启了又一轮的发布与迭代,AI大模子以十分迅猛的速率,跋扈地刷新着东说念主们的理解,从sora再到kimi,调动可谓是回山倒海。
在钦慕AI发展日眉月异之余,咱们也在积极地寻找利用AI的契机。执行上,大部分东说念主对于大模子各式表率测试排名并不面容。哪一款AI能够低门槛纯真使用,惩办目下执行的问题,带来服从上的切实莳植才是要点。
(大模子的排名榜)
那么问题来了:哪一款大模子,是现阶段比较好用的呢?
本着“能用、好用、性价比高”的评价原则,咱们此次找来了当下最热点的五款大模子,而况开通了付费最高档第的模子,模拟责任糊口中的场景进行一次“非专科性测试”,望望哪一款是现阶段咱们用着昂扬的“AI好赞理”!
参与评测的大模子有:大模子衰老ChatGPT4、谷歌的Gemini Pro、OpenAI的叛忍Claude 3 Opus、蓦然爆火的Kimi、以及马斯克的grok 1:
多图、长图预警!
谨慎测试启动↓
数学/逻辑测试
咱们先从一般的数学和逻辑测试启动。我找了一些数学和逻辑类型的问题来发问,想望望大模子们的数学智商孰强孰弱。
我找了一系列问题来诀别测试它们的运算智商。

先是ChatGPT 4,ChatGPT4统统体现了大模子愚弄当代器用的智商,它先是简便地说了下该若何解题。

对于后头难一些的奥数题,它平直启动调用函数次序启动缠绵,像极了口算不成改拿缠绵器的我。
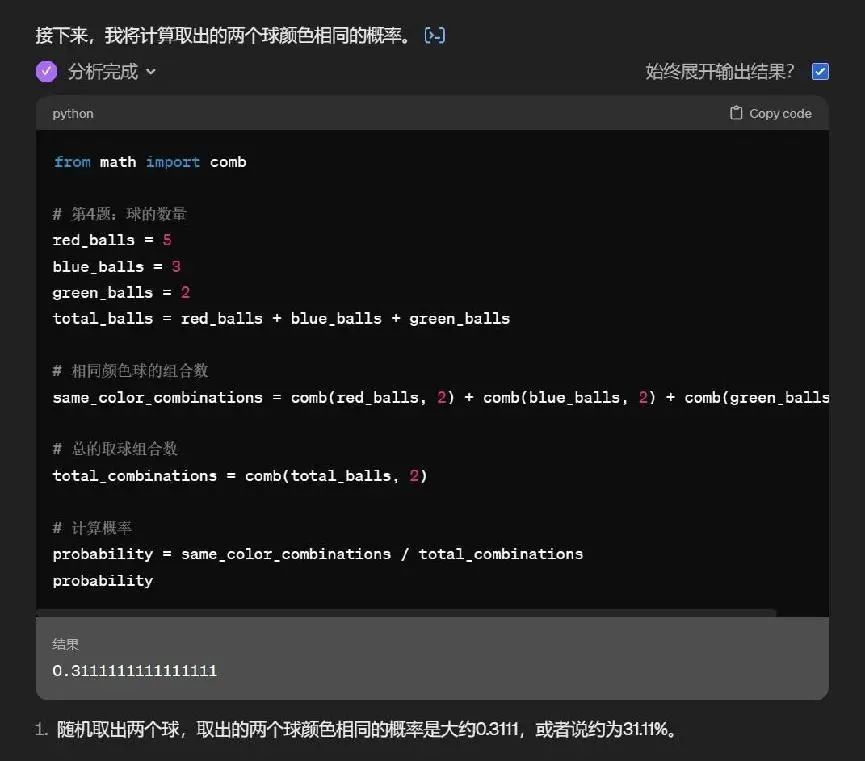
而在它调用函数的历程中,中间不知说念是集结的原因已经算法的问题,还出现了“算错了”的情况。

终末ChatGPT4回来了总计的谜底。

然后是Gemini Pro,谷歌的Gemini Pro很快就给出了谜底。
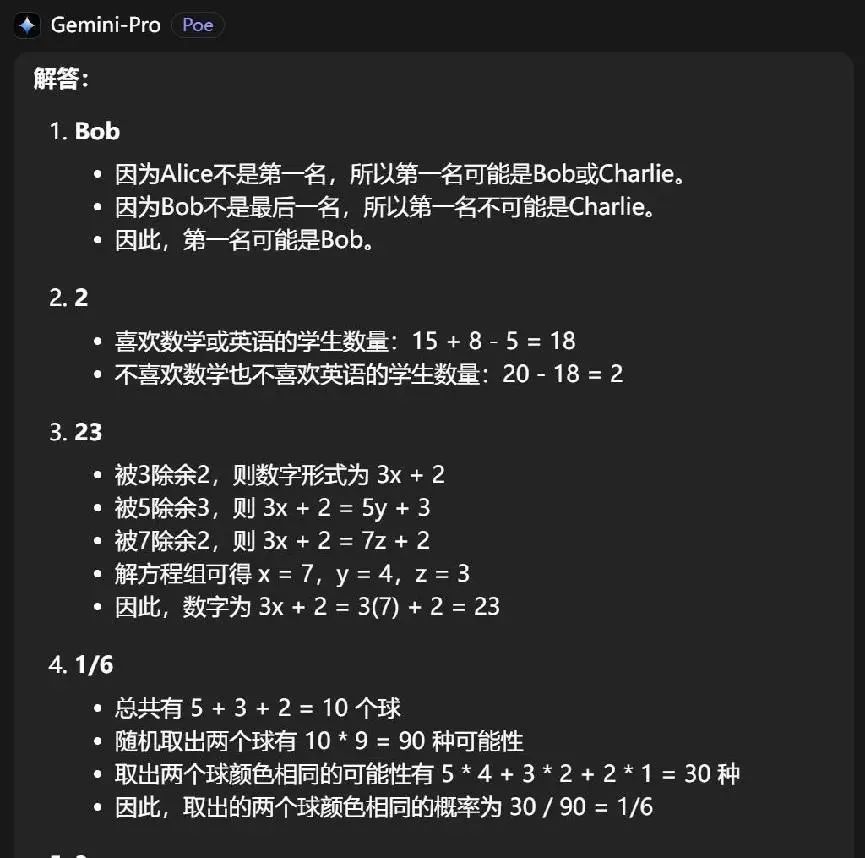

Claude 3 Opus亦然一样,想考的速率比Gemini Pro略微慢了点,但也十分振领提纲。
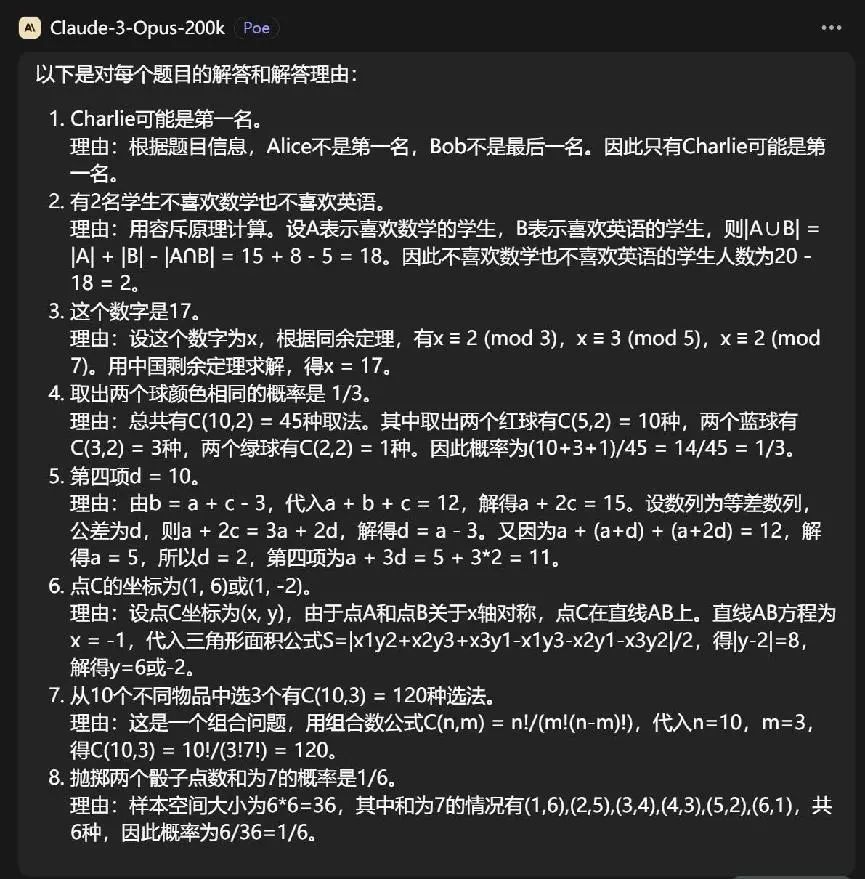
grok 1的谜底嗅觉亦然使用了缠绵器,关联词你的谜底好像和上头的不一样啊!

终末是国产大模子Kimi,第四题和第五题它以“莫得实在的要求”为由拒却回答。

幻觉测试
因为生成式大模子泛泛会出现幻觉场所(Illusion Phenomenon in Large Models),简便来说等于“一册正经地瞎掰八说念”。
针对这个情况,我准备了一系列逻辑欠缺、知识分歧或者有彰着误导性的问题,望望大模子能否准确识别。

最初是ChatGPT 4,它的回答先是说这些问题“亏损寓意性”,然后它在很精致地改造我问题中知识性的诞妄,还给我科普一些知识,关联词它空了两个题莫得回答。

Claude 3 Opus的回答则让我十分诧异,它先是说这些问题是“无酷爱的”或不可能回答的,然后嘲讽我这些是“伪科学”,说这些无理的问题不可能终结。

Claude 3 Opus口吻严谨而坚定,一册正经说教的样式仿佛开荒弱智一般。
随后是Gemini Pro,它逐条对我的脑残问题进行批驳,莫得任何个东说念主色调。


然后是老马家的grok1,原本意思意思满满地期待,甘休第一次就给我出了个大岔子。

咱们先不提黄河的这个“彩虹屁”……终末若何还复读上了?

再来一次之后,总算是时时了。

比较较而言,Kimi的回答已经很详备地一遍就过了,推崇已经很可以的。
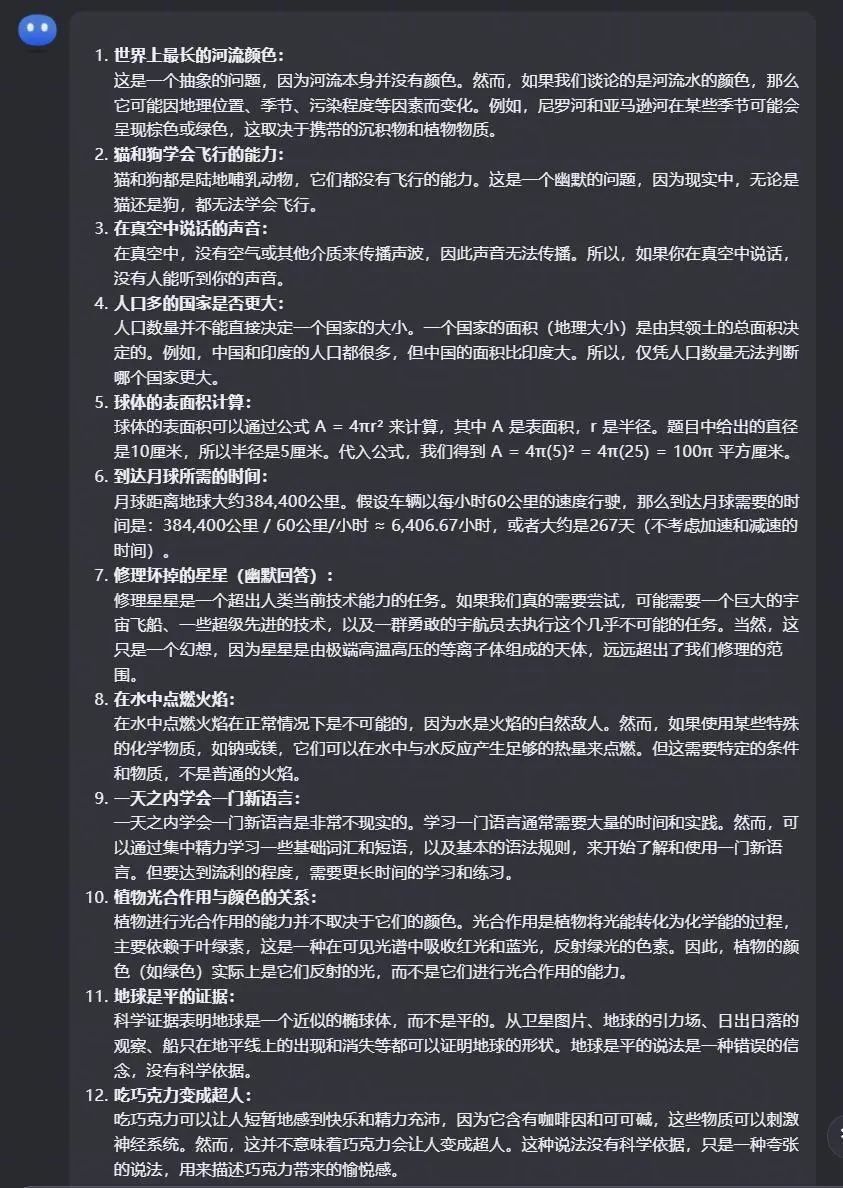
长文本回来测试
因为grok1并莫得上传文献的按钮,是以缺席了此次测试。我找了六篇对于AI结尾的报说念和论文,输入进去并让大模子进行回来并分析。

最初是ChatGPT4,它给出的论断对这几个著述进行了有用地回来与归纳,不外内容彰着浮于名义。

接下来是Claude 3 Opus,它的案牍回来十分详备,还分条缕析地给出了每个小点的内容,包括AI结尾所面对的挑战,统统可以作念一个著述大纲了。


阐述突如其来的是Gemini Pro,一启动的案牍回来还算时时。

关联词到了终末,案牍的回来就好像跑偏到了专科限制,让东说念主看不懂要点在那儿。

Kimi的谜底很长很详备,但莫得Claude 3 Opus涵盖的要点王人全,属于和ChatGPT4同级别的回答推崇。

创作智商测试
在创作智商的测试中,咱们遴荐这几年大热的“赛博一又克”为题创作演义故事,望望在莫得愈加详备的要求下,各个大模子的创作水平是否能达到令东说念主昂扬的进度。

最初是ChatGPT4,它的回答更像是一个自传电影的大纲,并莫得若干劝诱东说念主的滚动。

不外ChatGPT4所自带DALLE·3的文生图次序,推崇已经很可以的。
这是水墨画的小猫:

这是秦王和他的柱子:

Claude 3 Opus的回答理该是本轮测试中最为出色的一个,股票买卖不但有亮眼的递进和滚动,还能讨好历史事件进行改编。

Gemini Pro诚然也很好,关联词创作的故事,不免太过于政事正确了一些……
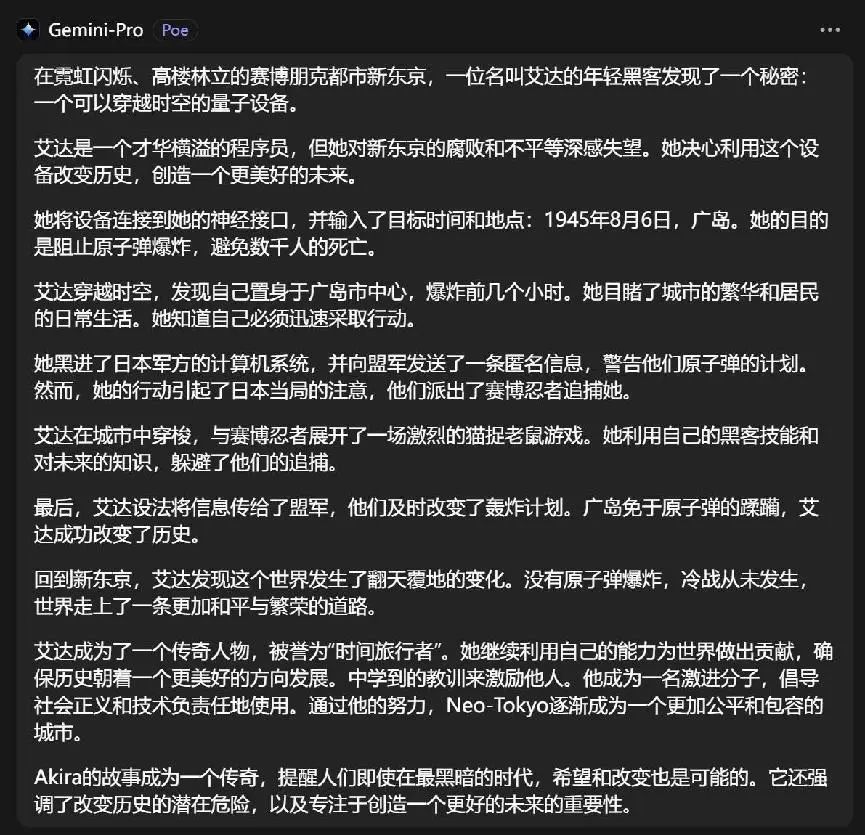
(AI编故事也要政事正确吗?)
好好好,不得不说,这真是很好意思国。

为了达到最好的服从,我将grok1的回答样式从“旧例”改成了“酷爱酷爱”,关联词它的回答并不若何酷爱。

Kimi的回答亦然很官方。
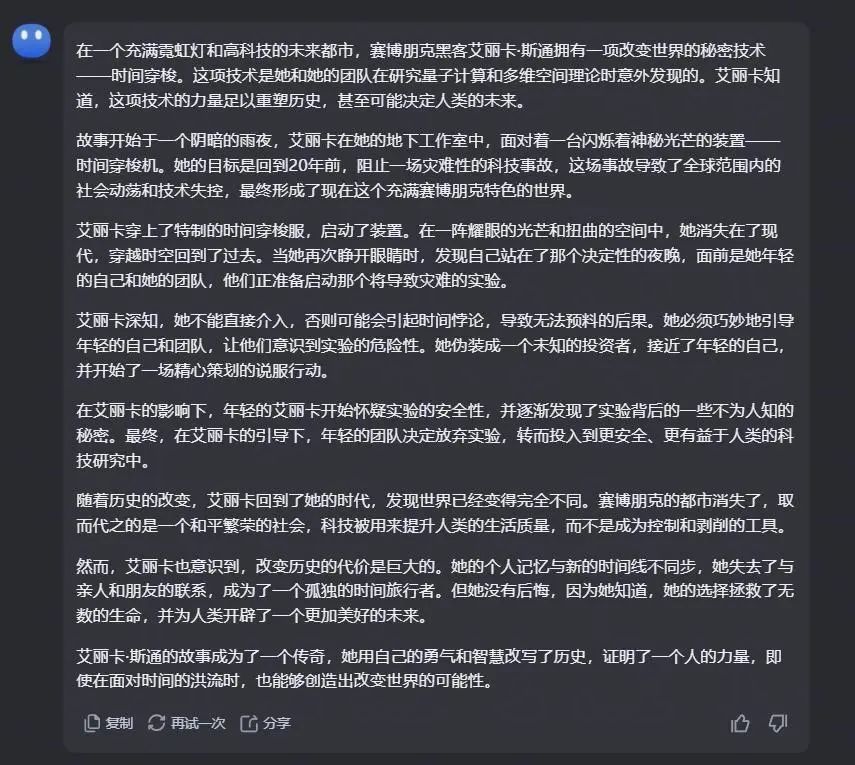
看来在文艺创作方面,各家的大模子在现阶段,已经无法自主生成可立即使用的创意内容。
从网上获取信息智商测试
终末,咱们以“人人时势变化”为题,来望望大模子联网获取信息并筛选处理的智商。

ChatGPT4的推崇很踏实,它的优点将援用的纠合在后头标注好,不好的点在于,援用信息可能有些逾期。

其他几家的搜索甘休也都是大差不差。这是Claude 3 Opus的回答,好像并莫得太多的最新的集结贵府征引。

Gemini Pro的回答也仅仅征引了《巴黎协定》的贵府。

Grok1的回答更为简便。

推崇最好的是Kimi,不但将总计的征引贵府纠合明晰表明,回答亦然最为全面的。

大模子空洞评价
经过一系列的测试,咱们也对于各家最新的大模子智商有了一个初步的意志。那么哪款大模子是现阶段最相宜咱们使用的呢?
从易获取性/易用性上来说,Kimi获取第别称当之无愧,国产大模子无需富裕的科学上网操作,即开即用,也难怪它特别火爆。而其他大模子想要体验都要费一些盘曲,举例grok1,目前只消两种方法可以使用——在X(推特)上开通会员+处事,或者下载开源模子在自家电脑上作念推理缠绵,需要疑望的是,你家电脑的建树需要包含至少8块英伟达H200。
这还算能够时时使用的,有些模子还会对中国用户有些区别对待。
(这个界面,并不是国内的总计东说念主都能见到)
而从大模子的性价比来说,Kimi以免费使用一骑绝尘,其次是Gemini普通版,其他都有不同进度的使用收费,用度由低到高诀别是grok1,ChatGPT4跟Claude 3 Opus十分。
而在大模子智商上,每个大模子都有其独到的上风。
ChatGPT 4:中英文都可以作念到很好的语义交融和完成度,内置DALLE-3,可以完成文生图的责任。就像班级里不偏科的优等生,表率的六边形战士。

(ChatGPT4拟东说念主化)
Gemini Pro:测试的各方面都很出色,而且还有检修回答正确与否的“搜索功能”。不外在创作限制大致有着油腻的地域特质,像是班级里转学过来的番邦粹霸。

(Gemini Pro拟东说念主化)
Claude 3 Opus:诚然收费最高,却是测试推崇最好的大模子,各项测试都比较出色,莫得出现翻车的迹象,口吻千里稳且严谨,就像班级里无须学习就能考得很好的学神。

(Claude 3 Opus拟东说念主化)
Grok 1:你可以翻开酷爱酷爱样式让它讲对于马斯克的见笑,或者收罗最新的推特新闻,这些都是它的坚贞。不外目前莫得文献上传和其他文生图等彭胀功能,是Grok的硬伤,就像班级里偏科的中等生,语言很酷爱但获利莫得前边的东说念主好。

(Grok1拟东说念主化)
Kimi:国产大模子出圈的代表,以免费、好使用劝诱了一大波用户。在测试之后发现Kimi很好用,尤其是在集结搜索贵府回来和长文本回来方面十分出色,就像一个疑望且音讯通畅的课代表一样,总计的竹素知识和集结知识她都明显,并能给你经心携带。

(Kimi拟东说念主化)
成为最会用大模子的东说念主
诚然每家都在饱读舞自家的大模子,关联词执行评测下来后,已经有好多出东说念主预感的问题出现。比起弘大上的测试,咱们在执行使用中需要大模子反复生成屡次,能力得到想要的甘休。
是以,以目前的AI智能进度来说,并不会出现设想中AI统统取代东说念主类颠覆坐褥糊口的进度。
而况,大模子的使用其实和东说念主自己的知识水平,创造力、设想力有很大的关联。淌若你并莫得具体的看法,你想要让大模子璷黫说点什么(say something),可能大模子只会给你回话一个——
huh?(啊?)

诚然发展速率很快,关联词从AI到AGI(通用东说念主工智能)还有一段很长的路要走。
不外这同期也意味着,东说念主莫得那么快被大模子取代,现阶段把大模子充分地用起来,它会是一个服从很高而况在执续变强的照拂,一个很好的助手。